pythonのopencvで画像重ね、回転、輪郭抽出する簡単サンプル
opencvで、いくつかやりたいことがあったので下調べとして作ってみました。 jupyter notebookで作ってます。
画像を重ねて描画
これを作ってみてわかったOpenCVの特徴。
- 画像データを読み込むとnumpy.ndarrayで返ってくる
- ピクセルの色データがB, G, R(Blue, Green, Red)の順に並んでいてRGBではない
PNG画像の透過部分を透過させて画像を描画
背景を水色にして、アルファ部分を透過してpng画像を重ねて描画。
PNG画像の透過部分を保持したまま画像を回転
PNG画像をJPG画像の上にリサイズ、回転させて透過描画
画像の回転、縮小、輪郭を抽出した矩形を描画
抽出した輪郭ぴったりに線を描画
参考
ども、ありがとうございます! stackoverflow.com
YOLOでMNISTを学習させてみる
YOLOでの学習の練習にMNISTの教師データを自前で作って学習させてみました。
必要なソフトのインストール
Kerasのインストール
KerasがPython環境に入っていない場合は入れてください。
pip install tensorflow pip install keras
darknet YOLOのインストール
darknet YOLOのリポジトリを取得する
git clone https://github.com/pjreddie/darknet
cd darken
make
ビルドなど、うまくいかない場合はdarknet YOLOの公式サイト参照。
学習データの作成
学習データを作成するためのスクリプトを作り、GitHubにあげました。 まずは、このリポジトリを取得。
git clone https://github.com/uchidama/MNIST-TrainDataForYOLO.git
とか。
[1] MNISTの画像とラベルの作成
python mnist_to_jpg_and_label.py
画像とラベルの入ったテキストファイルが7万枚ずつ作成されます。
[2] train.txt と test.txtの作成
python generate_train_txt_and_test_txt.py
訓練用の画像一覧 train.txt とテスト用の画像一覧 test.txtが作成されます。 以上で学習データの作成は終了です。
YOLOでの学習
[3] リポジトリのcfgディレクトリ、dataディレクトリ内のファイルをdarknetにコピー
cp cfg/tiny-yolo-mnist.cfg <darknet_dir>/cfg cp cfg/voc-mnist.data <darknet_dir>/cfg cp data/voc-mnist.names <darknet_dir>/data
tiny-yolo-mnist.cfg の上の方にあるbatch, subdivisionsをコメントアウトして切り替えておく
[net] # Training batch=64 subdivisions=2 # Testing #batch=1 #subdivisions=1
[4] <darknet_dir>/cfg/voc-mnist.dataを編集。2で作成したtrain.txt、test.txtにパスを通す
train = <path-to-mnist-train>/train.txt valid = <path-to-mnist-test>/test.txt
[5] 学習に使うトレーニング済のウェイトをダウンロードする
cd <darknet_dir> wget https://pjreddie.com/media/files/darknet19_448.conv.23
[6] 学習モデルの保存ディレクトリを作成
mkdir backup
[7] 学習する
./darknet detector train cfg/voc-mnist.data cfg/tiny-yolo-mnist.cfg darknet19_448.conv.23
backupディレクトリの中に学習したモデル(weights)が保存される。
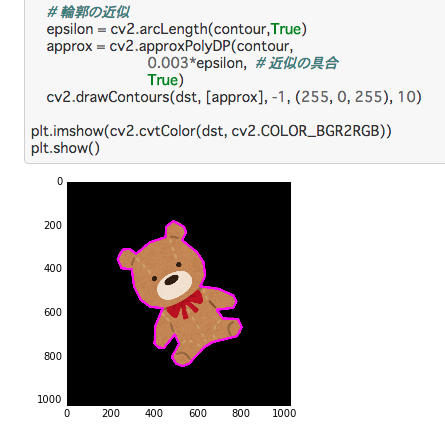
学習したモデルで識別する
./darknet detector test <data file> <cfg file> <weights> <predict image>
コマンドとしては、こういう指定。
./darknet detector test cfg/voc-mnist.data cfg/tiny-yolo-mnist.cfg weights/tiny-yolo-mnist_500000.weights ~/MNIST-TrainDataForYOLO/JPEGImages/60015.jpg
なんで、こんな感じで識別できます。
学習済のモデル
学習すると時間かかるんで、学習済みの重みもGitHubに置いときました。 https://github.com/uchidama/MNIST-TrainDataForYOLO/blob/master/weights/tiny-yolo-mnist_500000.weights
参考
KerasのMNISTデータをJPEGに書き出す簡単サンプル
MNISTをサンプルの学習データ作りで画像に書き出したかったんで、やってみました。
ソースコード
Keras使ってるんでシンプルに出来てます。
ついでにFashion-MNISTも書き出してみる
まぁついでなんで、ちょっとだけ書き換えてやってみました。
参考
参考になりました!ありがとうございますー。
ウェブカメラの画像をVGG16で画像認識させる簡単サンプル
Kerasにはダウンロードできる学習済みモデルがあることに気がついて
「あ、これにウェブカムからの画像を入れれば色々認識できるじゃん?」
と思い、作ってみました。
VGG16とは
- ImageNetから学習した畳み込みニューラルネットワーク
- 画像を1000クラスに分類する
- 入力画像のサイズは224x224
ソースコード
jupiter notebookで作ってます。
ウェブカメラの画像を出したら、上の停止ボタン(■ボタン)を一回押すと写真が撮れるので、そこから再生ボタン(▶︎ボタン)を押して処理を進めてください。
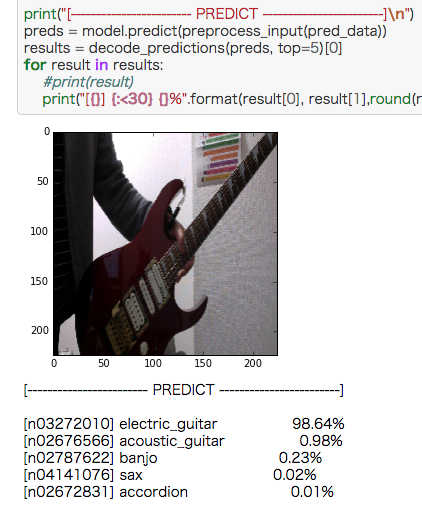
エレキギター、綺麗に認識したなぁ。
いろいろ試してみた

象のフィギアがあったんで撮ってみました。
認識結果は微妙に惜しいですね。

カメラは上手くいってる。

ショベルカーのおもちゃ。
チェンソー、パワードリルと工具系っていうのは系統としてあってる。

ハサミ。
ハードディスクと認識。写真の裏にMIDIコントローラーの裏のシルバーを使ってるせいでラップトップとかソレ系と認識してるんだろう。

ボールペンは認識成功。

SDガンダムのプラモ。warplaneは、ちょっと惜しい。
参考
無茶参考になりました。ありがとうございます!
ウェブカメラの画像をCIFAR-10で学習したニューラルネットワークで画像認識させる簡単サンプル
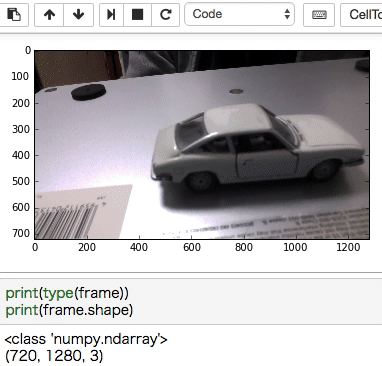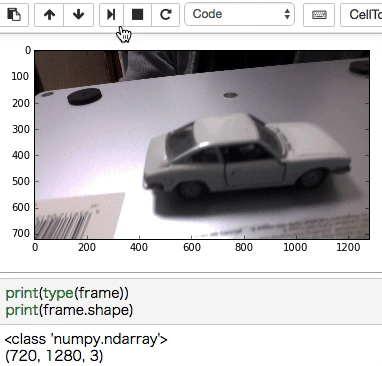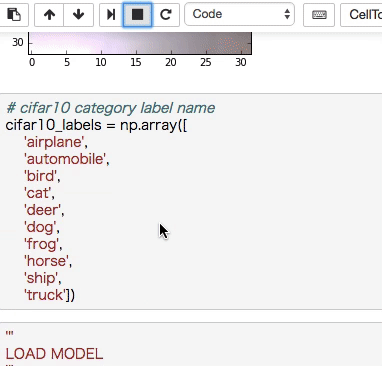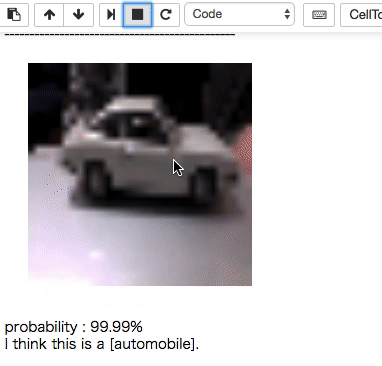
ウェブカムからの画像を識別するのを作ってみるかなと思いやってみました。
CIFAR-10のクラスラベルは次の10クラス。
- [0] airplane (飛行機)
- [1] automobile (自動車)
- [2] bird (鳥)
- [3] cat (猫)
- [4] deer (鹿)
- [5] dog (犬)
- [6] frog (カエル)
- [7] horse (馬)
- [8] ship (船)
- [9] truck (トラック)
なので、この10クラスのうちのどれかが認識できるということになります。
ソースコード
jupiter notebookで実行してください。
ウェブカムのプレビューがされたら、写たいものを写して■ボタンを押す。その後▶︎ボタンで先に進んで実行してください。
こちらがミニカーを写して認識させてみた例。
こちらが飛行機のおもちゃを認識させてみた例。
上のミニカーとソースコードは同じ。
GitHub
このリポジトリに学習済みのモデルデータふくめ一通り入ってます。
参考
Thanks!
Kerasデータセットのロイターニュースワイヤーの元文章を表示する簡単サンプル作ったが、トピックのラベルが謎

ロイターのニュースのデータもKerasに入ってることに気がついたんで、元文章の表示プログラムを書いてみました。
ロイターのニュースワイヤートピックス分類データセットとは
- 46のトピックにラベル付けされた,11228個のロイターのニュースワイヤーのデータセット
- IMDBデータセットと同様、ニュース文言は前処理済みで,各レビューは単語のインデックス(整数)のシーケンスとなっている
- 単語はデータセットにおいての出現頻度によってインデックスされている。そのため例えば,整数"3"はデータの中で3番目に頻度が多い単語である
- トレーニングデータが8982個、テストデータが2246個
ロイターニュースの元文章を表示するソースコード
IMDBと一緒なんで表示自体は瞬間的にできたんですが、ハマったのがラベル。
ロイターデータセットのラベルの数字は何なの?
ラベルの数字(y_train、y_test)を、これが指すトピックの文言に変換して表示するようにしようと思ったんです。なんでネットをいろいろ検索してみたんですが、この数字が何に対応しているのかサッパリわからない。1時間くらい粘ってあきらめました。
stackoverflow.com stackoverflowの質問も、なぜかスルーされてる。
誰か知ってる人、教えてください〜。
参考
IMDBを畳み込みニューラルネットワーク他で判定する簡単サンプル
 KerasにはIMDBの学習を行うサンプルが5個も入ってます。
KerasにはIMDBの学習を行うサンプルが5個も入ってます。
なので、せっかくだから作ってみました。
IMDBの学習方法
Kerasのexamplesの中に
- imdb_lstm.py (LSTM)
- imdb_fasttext.py (FASTTEXT)
- imdb_cnn.py (CNN)
- imdb_cnn_lstm.py (LSTM)
- imdb_bidirectional_lstm.py (Bidirectional_LSTM)
と5つ、学習を行うコードが入っています。
このコードにモデル保存を追記しIMDBを学習させます。
この部分のコードについては、このブログエントリーでは触れません。
後述のGitHubリポジトリにコードが入っていますので、そちらを参照してください。
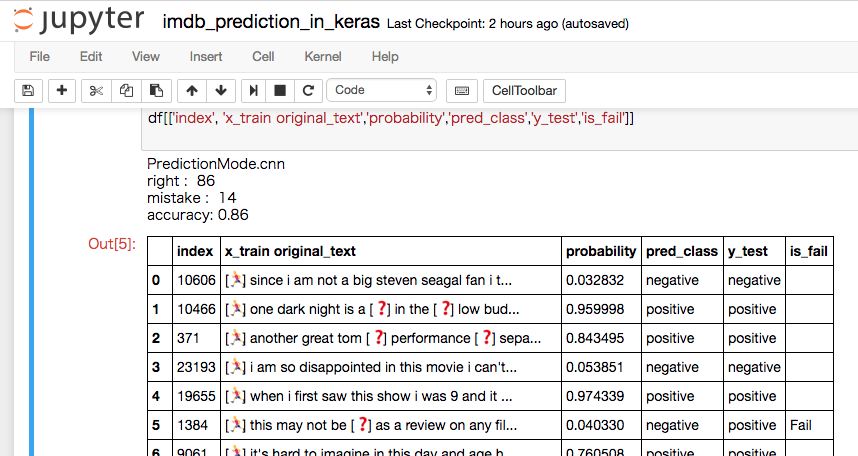
学習したモデルを読み込んでIMDBを識別するコード
jupyter notebookで使えます。
コード内のprediction_mode変数の値を切り替えることで、読み込む学習済みモデルを変更することができます。
GitHubリポジトリ
ここに全てのコード、バイナリが入っています。
学習モデルの比較
学習ログから、テストデータの正答率(val_acc)を比較したところimdb_fasttext, imdb_cnnの順で成績が良かった。
5つの学習モデルのログは、こちらのGoogleスプレッドシートで見ることができる。
Train-Log-IMDB-Prediction-In-Keras