KerasデータセットのIMDB映画レビューの元文章を表示する簡単サンプル
IMDBは触ったことがなかったんで、とりあえずデータセットの中身をみるところから始めてみました。
IMDB映画レビュー感情分類データセットとは
- 感情 (肯定/否定) のラベル付けをされた,25,000のIMDB映画レビューのデータセット
- レビューは前処理済みで,各レビューは単語のインデックス(整数)のシーケンスとなっている
- 単語はデータセットにおいての出現頻度によってインデックスされている。そのため例えば,整数"3"はデータの中で3番目に頻度が多い単語である
- ラベルが1ならば肯定的な意見。0ならば否定的な意見
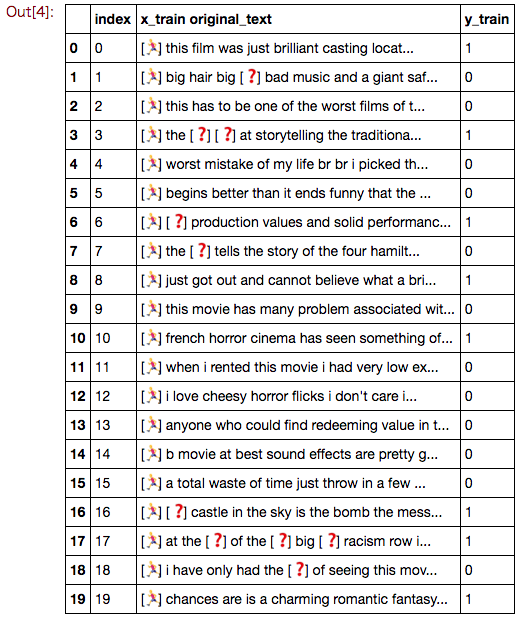
さて、コードを書いて実際どのようなデータが入っているか見てみます。
IMDBの元文章を表示するソースコード
x_trainが文章を出現頻度を表す整数のインデックスに変換したもの。
y_trainが感情の肯定、否定ラベルであることがわかる。
x_test、y_testは学習結果のテスト用データだが、このテストデータも25000件用意されていることがわかる。
参考
大筋ここにのってるコードをベースに、自分好みにすり合わせ。
ありがとう!