ウェブカメラの画像をVGG16で画像認識させる簡単サンプル
Kerasにはダウンロードできる学習済みモデルがあることに気がついて
「あ、これにウェブカムからの画像を入れれば色々認識できるじゃん?」
と思い、作ってみました。
VGG16とは
- ImageNetから学習した畳み込みニューラルネットワーク
- 画像を1000クラスに分類する
- 入力画像のサイズは224x224
ソースコード
jupiter notebookで作ってます。
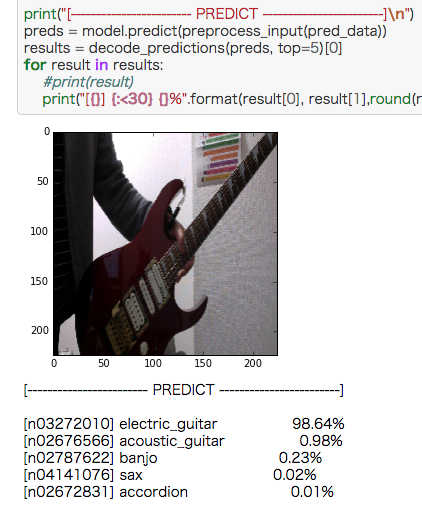
ウェブカメラの画像を出したら、上の停止ボタン(■ボタン)を一回押すと写真が撮れるので、そこから再生ボタン(▶︎ボタン)を押して処理を進めてください。
エレキギター、綺麗に認識したなぁ。
いろいろ試してみた

象のフィギアがあったんで撮ってみました。
認識結果は微妙に惜しいですね。

カメラは上手くいってる。

ショベルカーのおもちゃ。
チェンソー、パワードリルと工具系っていうのは系統としてあってる。

ハサミ。
ハードディスクと認識。写真の裏にMIDIコントローラーの裏のシルバーを使ってるせいでラップトップとかソレ系と認識してるんだろう。

ボールペンは認識成功。

SDガンダムのプラモ。warplaneは、ちょっと惜しい。
参考
無茶参考になりました。ありがとうございます!
ウェブカメラの画像をCIFAR-10で学習したニューラルネットワークで画像認識させる簡単サンプル
ウェブカムからの画像を識別するのを作ってみるかなと思いやってみました。
CIFAR-10のクラスラベルは次の10クラス。
- [0] airplane (飛行機)
- [1] automobile (自動車)
- [2] bird (鳥)
- [3] cat (猫)
- [4] deer (鹿)
- [5] dog (犬)
- [6] frog (カエル)
- [7] horse (馬)
- [8] ship (船)
- [9] truck (トラック)
なので、この10クラスのうちのどれかが認識できるということになります。
ソースコード
jupiter notebookで実行してください。
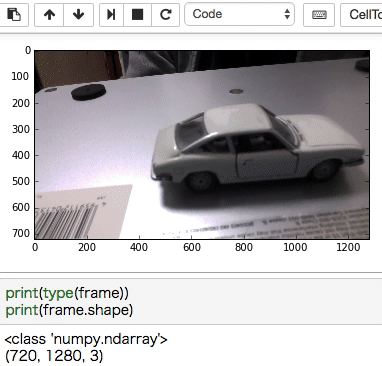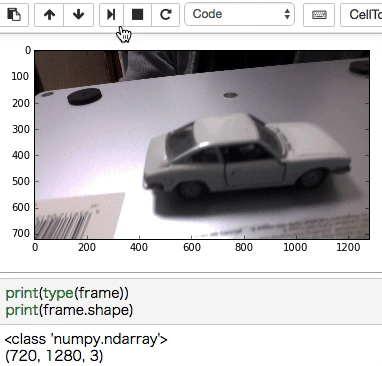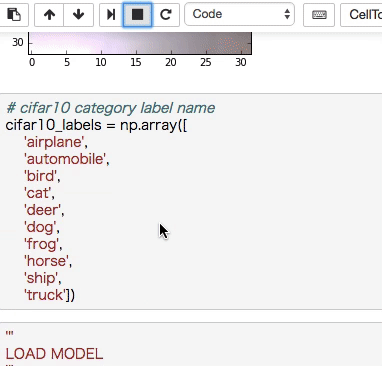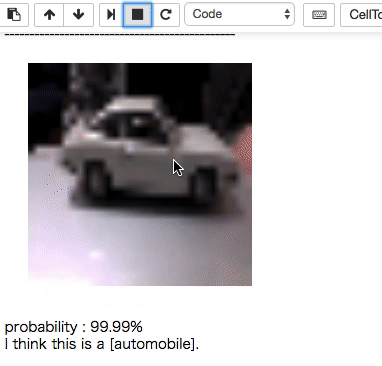
ウェブカムのプレビューがされたら、写たいものを写して■ボタンを押す。その後▶︎ボタンで先に進んで実行してください。
こちらがミニカーを写して認識させてみた例。
こちらが飛行機のおもちゃを認識させてみた例。
上のミニカーとソースコードは同じ。
GitHub
このリポジトリに学習済みのモデルデータふくめ一通り入ってます。
参考
Thanks!
Kerasデータセットのロイターニュースワイヤーの元文章を表示する簡単サンプル作ったが、トピックのラベルが謎

ロイターのニュースのデータもKerasに入ってることに気がついたんで、元文章の表示プログラムを書いてみました。
ロイターのニュースワイヤートピックス分類データセットとは
- 46のトピックにラベル付けされた,11228個のロイターのニュースワイヤーのデータセット
- IMDBデータセットと同様、ニュース文言は前処理済みで,各レビューは単語のインデックス(整数)のシーケンスとなっている
- 単語はデータセットにおいての出現頻度によってインデックスされている。そのため例えば,整数"3"はデータの中で3番目に頻度が多い単語である
- トレーニングデータが8982個、テストデータが2246個
ロイターニュースの元文章を表示するソースコード
IMDBと一緒なんで表示自体は瞬間的にできたんですが、ハマったのがラベル。
ロイターデータセットのラベルの数字は何なの?
ラベルの数字(y_train、y_test)を、これが指すトピックの文言に変換して表示するようにしようと思ったんです。なんでネットをいろいろ検索してみたんですが、この数字が何に対応しているのかサッパリわからない。1時間くらい粘ってあきらめました。
stackoverflow.com stackoverflowの質問も、なぜかスルーされてる。
誰か知ってる人、教えてください〜。
参考
IMDBを畳み込みニューラルネットワーク他で判定する簡単サンプル
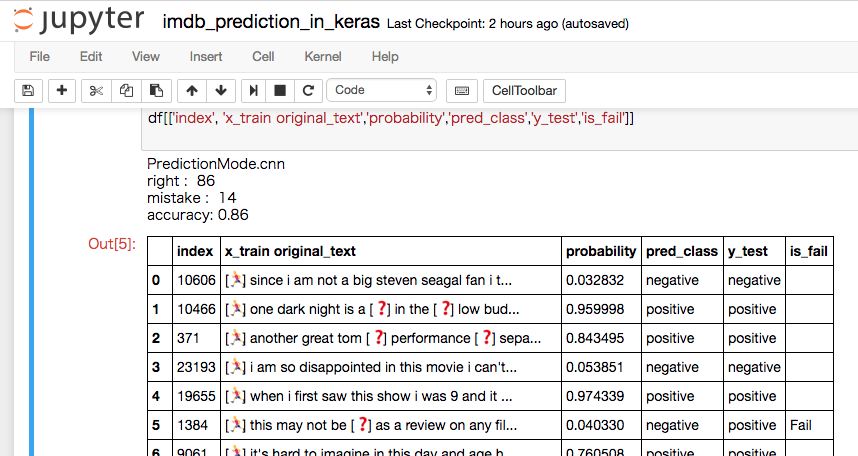 KerasにはIMDBの学習を行うサンプルが5個も入ってます。
KerasにはIMDBの学習を行うサンプルが5個も入ってます。
なので、せっかくだから作ってみました。
IMDBの学習方法
Kerasのexamplesの中に
- imdb_lstm.py (LSTM)
- imdb_fasttext.py (FASTTEXT)
- imdb_cnn.py (CNN)
- imdb_cnn_lstm.py (LSTM)
- imdb_bidirectional_lstm.py (Bidirectional_LSTM)
と5つ、学習を行うコードが入っています。
このコードにモデル保存を追記しIMDBを学習させます。
この部分のコードについては、このブログエントリーでは触れません。
後述のGitHubリポジトリにコードが入っていますので、そちらを参照してください。
学習したモデルを読み込んでIMDBを識別するコード
jupyter notebookで使えます。
コード内のprediction_mode変数の値を切り替えることで、読み込む学習済みモデルを変更することができます。
GitHubリポジトリ
ここに全てのコード、バイナリが入っています。
学習モデルの比較
学習ログから、テストデータの正答率(val_acc)を比較したところimdb_fasttext, imdb_cnnの順で成績が良かった。
5つの学習モデルのログは、こちらのGoogleスプレッドシートで見ることができる。
Train-Log-IMDB-Prediction-In-Keras
参考
KerasデータセットのIMDB映画レビューの元文章を表示する簡単サンプル
IMDBは触ったことがなかったんで、とりあえずデータセットの中身をみるところから始めてみました。
IMDB映画レビュー感情分類データセットとは
- 感情 (肯定/否定) のラベル付けをされた,25,000のIMDB映画レビューのデータセット
- レビューは前処理済みで,各レビューは単語のインデックス(整数)のシーケンスとなっている
- 単語はデータセットにおいての出現頻度によってインデックスされている。そのため例えば,整数"3"はデータの中で3番目に頻度が多い単語である
- ラベルが1ならば肯定的な意見。0ならば否定的な意見
さて、コードを書いて実際どのようなデータが入っているか見てみます。
IMDBの元文章を表示するソースコード
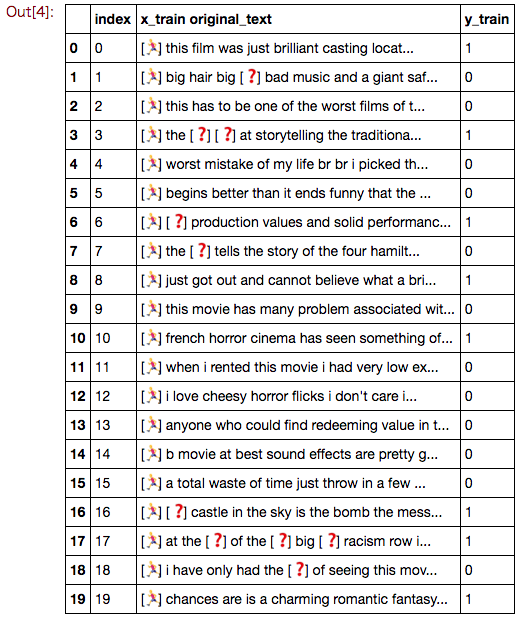
x_trainが文章を出現頻度を表す整数のインデックスに変換したもの。
y_trainが感情の肯定、否定ラベルであることがわかる。
x_test、y_testは学習結果のテスト用データだが、このテストデータも25000件用意されていることがわかる。
参考
大筋ここにのってるコードをベースに、自分好みにすり合わせ。
ありがとう!
畳み込みニューラルネットワークでのFashion-MNISTの学習をひたすら廻してみた結果

前回の記事
Fashion-MNISTを畳み込みニューラルネットワークで判定する簡単サンプル - 人工知能プログラミングやってくブログ
に対して
「val_lossがまだ0.2もあるんだから、もっと学習回せば正答率あがんじゃないの?」
という意見をもらったんで、
「じゃ、試しにやってみるか」
と徹底的に学習を回してみました。
その結果を発表します。
学習コード
kerasのexampleに入ってるmnist_cnn.pyをベースにちょっと書き換えたもの。
次のような変更がされている。
- MNISTではなくてFashion-MNISTのデータから学習する(当然)
- 引数で学習回数(epochs)を指定できるようにした
- 学習ログをcsvで出力する
学習回数 12エポック
前回の記事で「コスパ的にこの学習回数がベストっぽい」という結論に一回なった12エポックの学習グラフ。
val_accの最大値は、0.9236。
学習回数 24エポック
val_accの最大値は、0.9325。 val_lossも上がってないし、成績的にはこっちの方がちょっと良くなってるから、これも良い。
学習回数 64エポック
すでにval_lossが上がってきてて過学習の傾向が見られる。
val_accの最大値は、0.9371。
学習回数 128エポック
まぁval_loss上がっちゃってますね。
val_accの最大値は、0.9343。
学習回数 256エポック
val_accの最大値は、0.9383。
学習回数 512エポック
val_accの最大値は、0.9381。
学習回数 1024エポック
val_accの最大値は、0.9378。
学習回数 2048エポック
val_accの最大値は、0.9364。
val_lossは0.6近くまで上がってきてて、激しく過学習気味。
学習回数に関する総評
結果から考えるに、このニューラルネットワークの構造でFashion-MNISTを学習したとき、93%くらいの正答率しか出ないということだろう。
データとニューラルネット構造の兼ね合いで、だいたい出るであろう最大の成績は決まっていて、割と早い段階でその数値には達してしまうと考えて良いのだろうと思う。
そして、その段階に到達してしまった後はマシンパワーを使って学習を回してもval_lossが上がって過学習になってしまい、電力の無駄遣いにしかならないということのようだ。
例外もあるかもしれないけど、今回の実験結果からは、そのように考えられる。
GitHubリポジトリ
こちら。
今回、学習してできたモデルのバイナリも入ってます。
Googleスプレッドシート
学習グラフの数値の元データが入っているGoogleスプレッドシートがコチラ。
drive.google.com
参考
stackoverflow.com KerasのトレーニングログをCSV形式で保存するやり方が書いてあるよ。
Fashion-MNISTを畳み込みニューラルネットワークで判定する簡単サンプル
 「Fashion-MNISTは、MNISTとほぼ同じで画像ファイルが違うだけだから、MNISTの畳み込みニューラルネットワークで判定できるだろうな」
「Fashion-MNISTは、MNISTとほぼ同じで画像ファイルが違うだけだから、MNISTの畳み込みニューラルネットワークで判定できるだろうな」
とは思ったんですが、一応確認のためにやってみました。
Fashion-MNISTをCNNで学習しモデルを保存
Kerasのエグザンプルに入っているmnist_cnn.pyをちょっと書き換えて作りました。
python fashion-mnist_cnn_train.py
実行すると学習が行われます。
学習したモデルを読み込んでFashion-MNIST画像を認識させるコード
jupyter notebookで使えます。
GitHubリポジトリ
ここに学習したモデル込みのコードを置きました。
学習回数に関する考察
12エポック回したモデルと24エポック回したモデルの二つをgithubのリポジトリに入れときました。 元にしたKerasのサンプル、mnist_cnn.py に元々書いてあったのは12エポック。 一応、倍回してみたらどんなもんだろうな?と24エポックも回して見ました。
学習時に出力されたloss, acc, val_loss, val_acc を表にまとめたのが次のもの。
で、注目すべきは学習後、テストした結果の成績であるval_lossとval_acc。
12エポックと24エポックの比較グラフが次のもの。
12エポックも24エポックもval_loss、val_accとも似たような値なので、12エポックがほぼ適正な学習回数のようだ。